



Trust, But Verify: Can We Make LLMs Trustworthy?
Trust, But Verify: Can We Make LLMs Trustworthy?
Chirag Shah
University of Washington
Like many others these days, I like trying out ChatGPT for fun. Mind you, for fun, but not for serious work. Of course, my definition of fun is perhaps different than yours. I like to probe ChatGPT (and other conversational agents) in different ways to see what they really know. For instance, I learned about this fun case relating to Tom Hanks’ mother. See that question and ChatGPT’s response below.
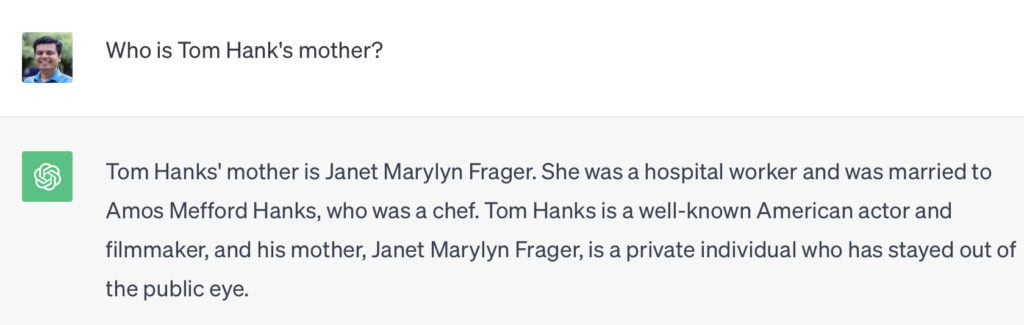
But if you ask ChatGPT about Janet Marylyn Frager separately, see what happens.
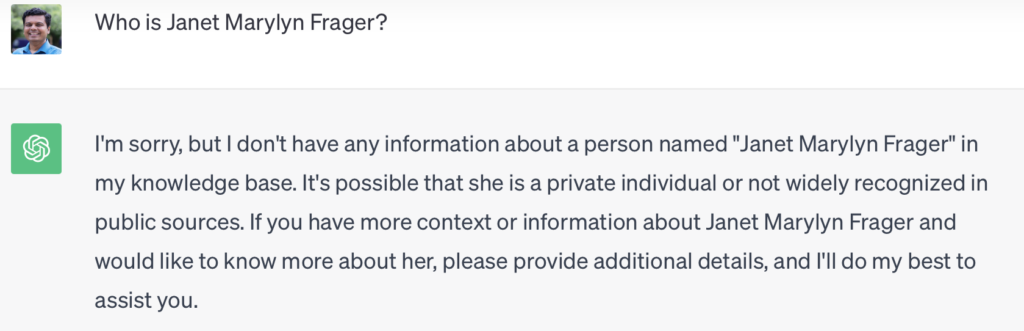
If you had such an interaction with a human, I’m sure it will leave you really puzzled. How can someone just tell me about a person and the very next moment don’t even know they exist? This is not the only example that I have come across recently that demonstrate that trusting LLMs blindly may not be the best idea. Let’s take one more example. This one is from a recent pre-print paper with my colleague Emily M. Bender. Take a look at what Google answers you for question about seizure. It even provides a source, which seems authoritative. You have no reason to not trust this answer.
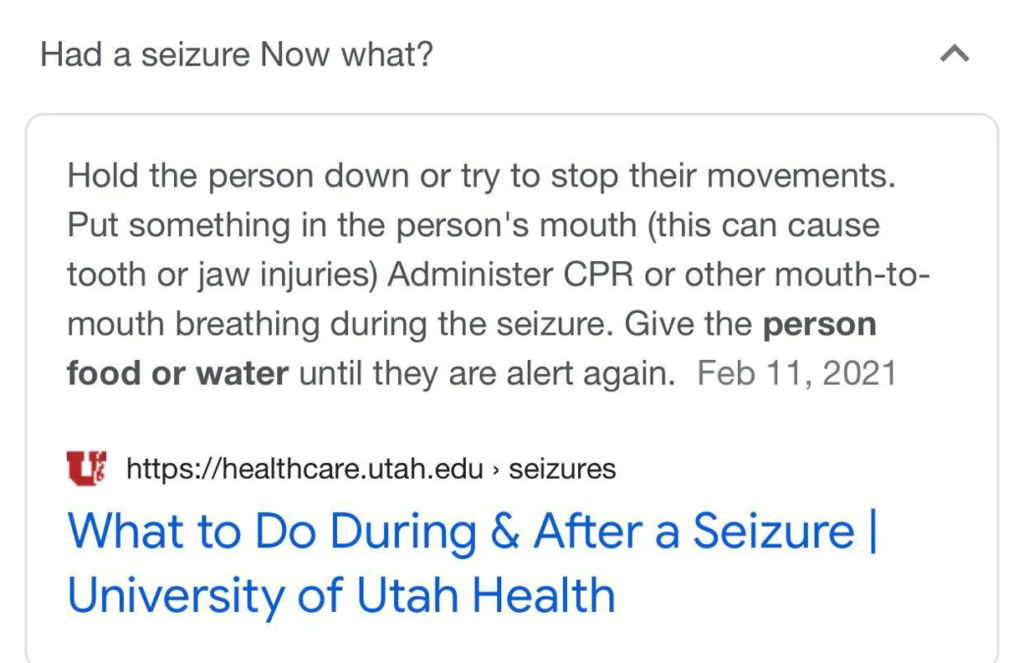
Well, it turns out that this answer not only has holes, but it’s entirely wrong. That’s not because of the original source, but what the system ended up extracting from that source. If you go to the source, what you see is below.

The answer extraction and generation system here missed a very important and critical context. All the steps are under “Do not.” Again, for a naive user, there is no reason to not trust the answer.
