



Can AI Help to Predict the Scholarly Impact of New Scientific Papers?
What Makes a Paper Influential?
Typically, scholarly impact is assessed by citation counts. To overcome the limitations of missing citation data, we leveraged SciBERT, a powerful AI model pre-trained on scientific texts, encoding the titles and abstracts of papers into high-dimensional vector representations. Using these representations, we introduced two novel indicators:
Topicality (τ) : Measures how closely a new paper aligns with trending high-impact research topics.
- Originality (σ): Assesses the uniqueness of research by measuring its conceptual distance from popular existing studies.
The calculation of these two indicators is based on mathematical measures of similarity and distance within the SciBERT-generated vector space. The specific framework is shown in the figure below.
Testing Our Method
Our method was validated using the COVID-19 Open Research Dataset (CORD-19), which includes over one million research articles across various scientific disciplines. This dataset was selected because it mirrors real-world conditions where rapid knowledge dissemination outpaces the availability of citation data.
Key Findings and Results
Through extensive experiments, we discovered several critical results:
- Superior Performance of SciBERT: Compared to traditional representation models (e.g., TF-IDF and Glove), SciBERT significantly improved representation accuracy, as demonstrated by:
- Below figure visualizes improved semantic relationships among words, showing clearer clustering of similar concepts.
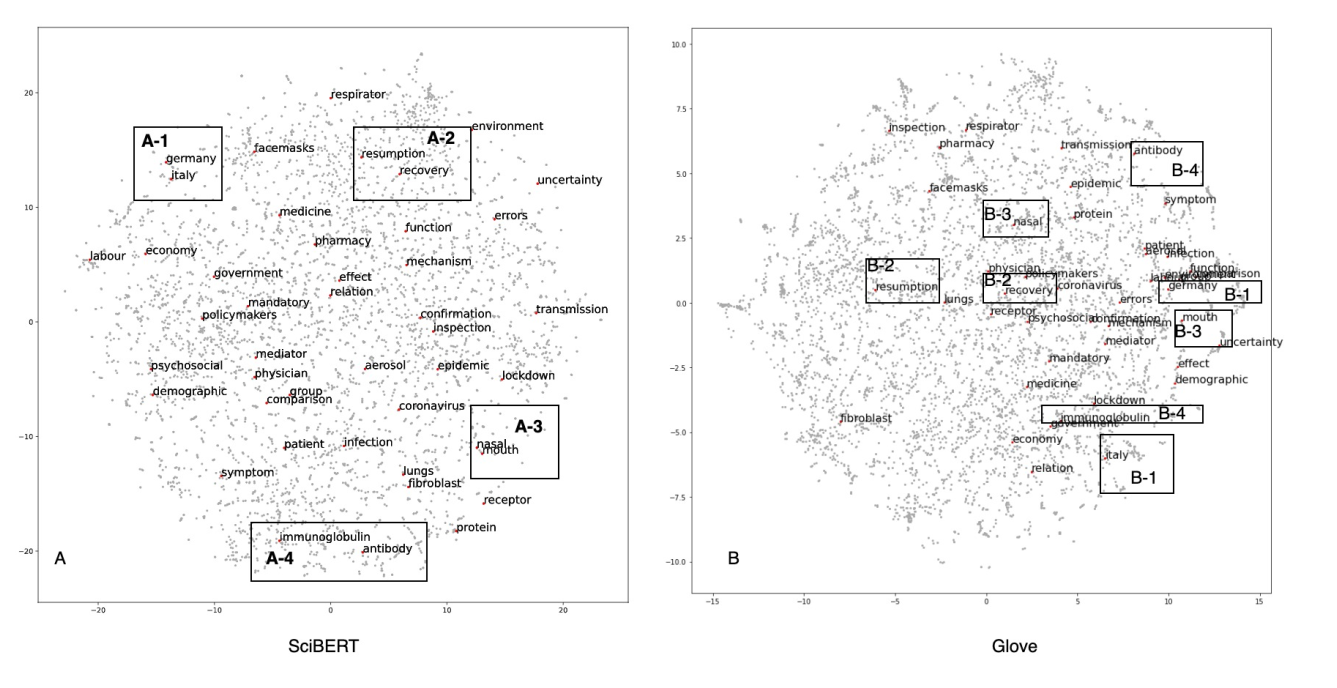
- Below figure visualizes improved semantic relationships among words, showing clearer clustering of similar concepts.
- Below figure illustrates consistent representation patterns within specific journals (e.g., “British Journal of Surgery” and “Nature Communications”), highlighting SciBERT’s effectiveness.

- Below figure demonstrates superior clustering capability for journal paper categorization compared to other models.

- Significant Predictive Indicators: Both Topicality (τ) and Originality (σ) correlated strongly with future scholarly impact:
- 6-month prediction: Regression analysis yielded coefficients of 5.4915 for Originality and 6.6879 for Topicality (both p<0.001).
- 12-month prediction: Coefficients increased significantly to 12.9964 (Originality) and 13.8678 (Topicality), again highly significant (p<0.001).
Insights from Simulation and Case Studies
Detailed simulations and case studies provided further insights: Papers with moderate originality (bridging multiple trending topics) or high originality (introducing completely novel research directions) had higher potential to become influential.
- A representative case study demonstrates that papers closely aligned to current hot topics or highly original papers (distinctly separate in representation space) tend to achieve greater scholarly impact.
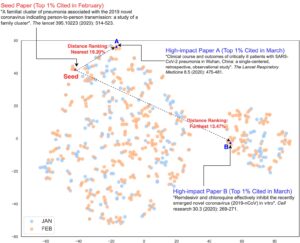
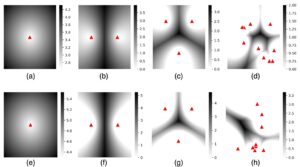
- Simulation results indicate: First, as research fields mature, potential areas for groundbreaking discoveries shrink. Second, interdisciplinary research, positioned between established research areas, holds significant potential for achieving high impact.
Broader Implications of Our Research
This research presents a significant advancement by providing a method to assess scholarly impact based purely on textual content, valuable for evaluating recent publications. Our findings enhance traditional metrics, allowing stakeholders to make informed decisions about early-stage research.
Moreover, our study sheds light on knowledge creation dynamics, suggesting that groundbreaking research often synthesizes existing knowledge in novel ways or ventures entirely into uncharted territory.
This article is based on the following paper: Jiang, Z., Lin, T., & Huang, C. (2023). Deep representation learning of scientific paper reveals its potential scholarly impact. Journal of Informetrics, 17(1), 101376.
The dataset, detailed methodology, and additional resources can be accessed at: https://github.com/Lintianqianjin/Text2Impact
