



Why Does Data Quality Matter? How to Evaluate and Improve Data Quality for Machine Learning Systems
Why is data quality important for machine learning?
Data quality is about the comprehensive characterization and measurement of quantitative and qualitative properties of data. In machine learning, it is about the characterization and measurement of the state of data for fitting the purpose of building a machine learning system. The importance of data quality in machine learning can be reflected in the following aspects: (1) The computing rule of “garbage in, garbage out” is still applicable to current machine learning systems. For example, the significant imbalance of the training datasets in skin colors has caused the gender classification system to produce a 0.8% error rate for recognizing the faces of lighter-skinned males but as high as 34.7% error rate for identifying the faces of darker-skinned females (Buolamwini & Gebru, 2018). (2) Poor data quality in high-stakes domains, such as safety, well-being, and stakes, has become a common and severe problem but did not get enough attention. For example, poor data practices reduced accuracy in IBM’s cancer treatment AI and led to Google Flu Trends missing the flu peak by 140% (Sambasivan et al., 2021). (3) Data-centric AI, powered by big data and computing infrastructure, is becoming mainstream (Whang et al., 2021). However, many datasets in the real world are of low quality, suffering from the data quality problems such as insufficient, dirty, biased, and even poisoned. Therefore, a systematic evaluation of the quality of the dataset is critical for building a high-quality machine learning system. The evaluation result would offer guidelines for data enhancement and system performance improvement.
A framework for data quality evaluation and improvement for machine learning
Data quality evaluation is important for machine learning, but it is also challenging since there are many dimensions to be evaluated, and the data quality issues cannot be resolved in a single step but throughout the entire machine learning process. In our study, we propose a practical framework that combines data quality evaluation, data quality improvement, and model development for constructing a high-performance machine learning system.
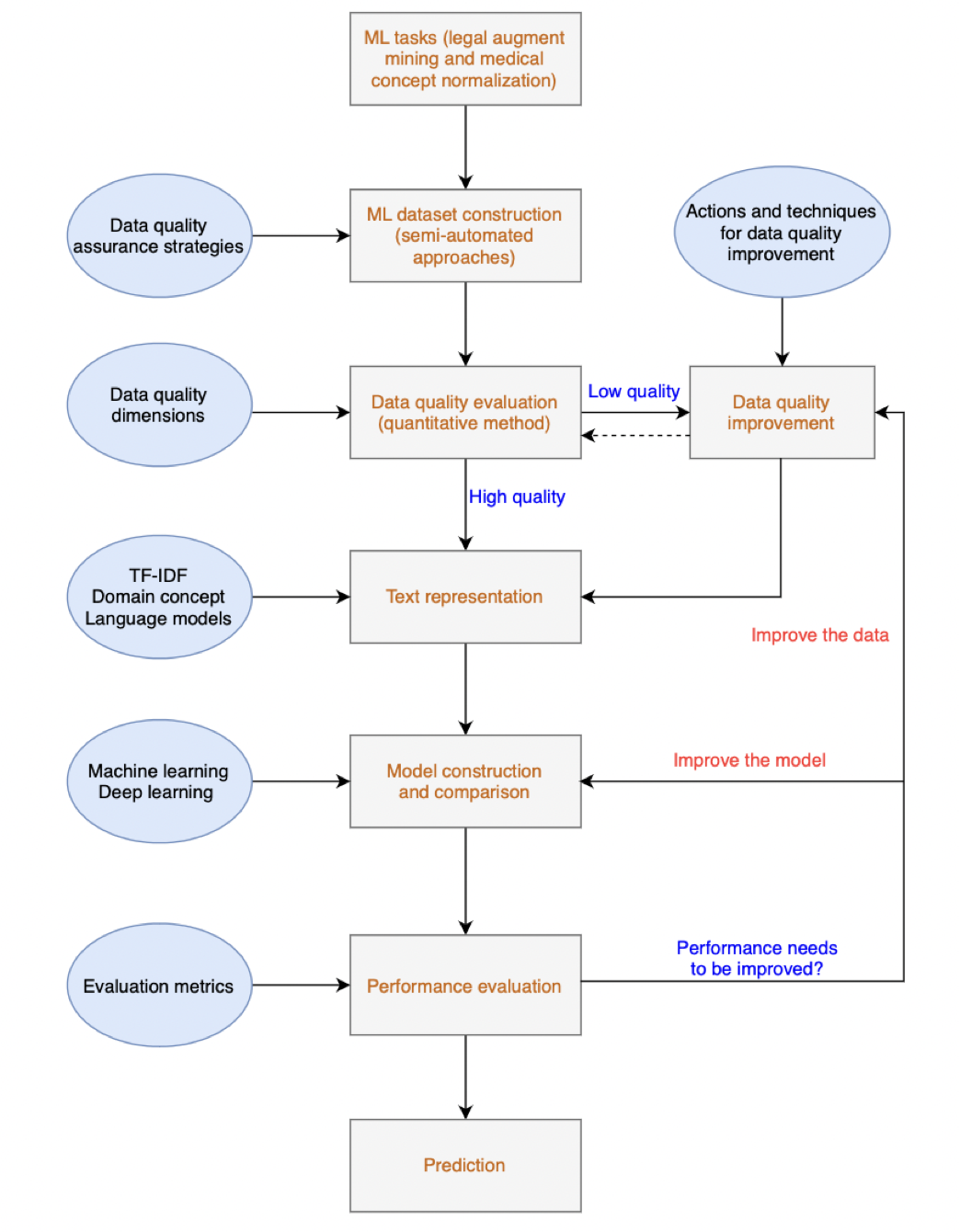
In the framework, the middle column presents the machine learning life cycle, starting from the task definition, then dataset construction, data quality evaluation, text representation, model construction, and performance evaluation. The left side of the framework demonstrates the elements, actions, and algorithms for supporting each step in the machine learning life cycle. Previous studies have ignored the data quality evaluation and improvement when building a machine learning system, leading to the unreliability of the constructed machine learning system. In our framework, data quality assurance strategies need to be designed to ensure data quality when creating a machine learning corpus. Meanwhile, selected data quality dimensions are used to evaluate the data quality rigorously. If the data quality meets a specific requirement, the workflow can continue to the next step. Otherwise, data quality improvements, such as deduplication, handling class imbalance, data augmentation, or fine-tuning, need to be implemented until it meets the quality requirement. However, “high-quality” data does not always guarantee a high-performance machine learning system. One reason might be that the “high-quality” has been wrongly claimed, the other might be that the machine learning model has been inappropriately selected. In this situation, we need to decide whether system performance can benefit more from improving the model or the data, which goes into the right side of the framework.
Rigorous experiments can be designed for data quality assurance in machine learning

Based on the proposed framework, we conducted two case studies in the medical domain and legal domain to demonstrate that rigorous experiments can be designed for data quality assurance in machine learning systems.
The first case study is for medical concept normalization. We reused two datasets in social media text: AskAPatient and TwADR-L. We first exposed the hidden quality problem in the two datasets used to build a machine learning system for normalizing medical concepts. The system was claimed to have achieved the best performance compared to existing work on a machine learning task. However, the results of our experiments showed that the “best performance” was due to the poor quality of the datasets and the defective validation process. To address the data quality issue and build a high-performance medical concept normalization system, we developed a transfer-learning-based strategy for data quality enhancement and system performance improvement. The results of the experiments showed a strong correlation between the quality of the datasets and the performance of the machine learning system. Meanwhile, when fine-tuning is applied to a pre-trained model, it is necessary to conduct an evaluation of the target datasets to ensure they are appropriate to the target-specific task.
The second case study is for legal argument mining. We created our own dataset, which has 4937 sentences from Texas criminal cases that were manually labeled. Several strategies were implemented to assure its quality. The initial results showed that class imbalance and insufficient training data are the two major quality issues that negatively impacted the quality of the system built on the data. We experimented and compared three class-imbalance-handling techniques and found that the mixed-sampling method, which combines up-sampling and down-sampling, was the most effective way to address the issue. To address the insufficiency of training data, we experimented with several machine learning methods for automated data augmentation including pseudo-labeling, co-training, expectation-maximization, and generative adversarial network (GAN). The results showed that GAN with deep learning models achieved the best performance. Finally, ensemble learning of different classifiers was proposed and experimented with for the construction of a legal corpus, which achieves higher quality in comprehensiveness, freshness, and correctness compared to existing work.
Best practice and guidance on building high-performance machine learning systems
Observed from our experiment results, we recommend ensuring the performance and reliability of machine learning systems from four aspects: data preparation, data quality evaluation, data quality improvement, and model selection.
- Data preparation for building a domain-specific machine learning system mainly includes four steps: (1) Selecting a data source or multiple data sources. (2) Collecting the data from the selected data source. (3) Labelling the data for training and testing. (4) Preprocessing the data as the model input.
- Data quality evaluation starts by selecting data quality dimensions, which can be reused from existing studies (Gudivada, Apon, & Ding). Not all the dimensions need to be evaluated; critical data quality dimensions should be selected based on different tasks and datasets. Some dimensions, such as reputation and freshness, can be estimated qualitatively, while others, such as variety, correctness, and consistency, can be evaluated using statistical methods. Other dimensions, such as sufficiency and comprehensiveness, might need to be evaluated by experimental study.
- Data quality improvement comes after data quality evaluation. The latter aims to identify the data issues, while the former aims to eliminate them. There are two approaches: (1) directly working on the initial datasets and (2) introducing new high-quality data to the initial datasets.
- Selecting an appropriate model is critical for machine learning performance. The model should be selected considering the amount of data demonstrated in our two case studies. Generally, language models, such as ULMFit and BERT, are better than TF-IDF for text representation in domain text classification tasks. However, a recent study found domain concepts might be better than language models for domain-specific tasks (Chen et al., 2022). As for model learning, deep learning models are superior in handling a large amount of data since complex architectures can be designed for feature learning and model training. However, when training is insufficient, semi-supervised learning strategies should be implemented for data augmentation.
The original articles on which this essay is based are:
Chen, H., Chen, J., & Ding, J. (2021). Data evaluation and enhancement for quality improvement of machine learning. IEEE Transactions on Reliability, 70(2), 831-847.
Chen, H., Pieptea, L. F., & Ding, J. (2022). Construction and Evaluation of a High-Quality Corpus for Legal Intelligence Using Semiautomated Approaches. IEEE Transactions on Reliability, 71(2), 657-673.
Chen, H. Data Quality Evaluation and Improvement for Machine Learning, dissertation, May 2022; Denton, Texas. (https://digital.library.unt.edu/ark:/67531/metadc1944318/: accessed September 21, 2022), University of North Texas Libraries, UNT Digital Library, https://digital.library.unt.edu.
References
Buolamwini, J., & Gebru, T. (2018, January). Gender shades: Intersectional accuracy disparities in commercial gender classification. In Conference on fairness, accountability and transparency (pp. 77-91). PMLR.
Chen, H., Wu, L., Chen, J., Lu, W., & Ding, J. (2022). A comparative study of automated legal text classification using random forests and deep learning. Information Processing & Management, 59(2), 102798.
Gudivada, V., Apon, A., & Ding, J. (2017). Data quality considerations for big data and machine learning: Going beyond data cleaning and transformations. International Journal on Advances in Software, 10(1), 1-20.
Makridakis, S. (2017). The forthcoming Artificial Intelligence (AI) revolution: Its impact on society and firms. Futures, 90, 46-60.
Sambasivan, N., Kapania, S., Highfill, H., Akrong, D., Paritosh, P., & Aroyo, L. M. (2021, May). “Everyone wants to do the model work, not the data work”: Data Cascades in High-Stakes AI. In proceedings of the 2021 CHI Conference on Human Factors in Computing Systems (pp. 1-15).
Whang, S. E., Roh, Y., Song, H., & Lee, J. G. (2021). Data Collection and Quality Challenges in Deep Learning: A Data-Centric AI Perspective. arXiv preprint arXiv:2112.06409.
