



Dissecting Harmful Memes on Social Media
The dark side of memes
Recent efforts like the Hateful Memes task [1] and Memotion Challenge [2] have set the tone for active explorations towards detecting hatefulness and emotions from memes. Besides these aspects, other studies encompass phenomena like offense, troll, and misogyny detection. However, hardly any work studies memes from either a broad perspective of “harmfulness,” or with respect to fine-grained aspects that facilitates more insightful interpretation of memes and their impact. An extensive survey on understanding and detecting harmful memes [3] proposes the following generalized definition:
Harmful Memes: Multimodal units consisting of an image and embedded text that has the potential to cause harm to an individual, an organization, a community, or society in general.

In addition to the hatefulness and offense, toxic memes could have broader harmful implications. For instance, the meme in Fig. (c) above is neither hateful nor offensive. However, it harms the media agencies depicted on the top left (ABC, CNN, etc.), as it builds the context on their comparison with allegedly authoritative state actors. In summary, the harmfulness of memes has broader implications and may encompass other aspects, such as cyberbullying, misinformation, etc. Moreover, harmful memes have a target (e.g., news organizations such as ABC and CNN in our previous example), which requires detailed analysis to decipher their underlying semantics and help with the explainability of the detection models.
This motivation leads to contemplating robust multimodal solutions that optimally address critical challenges posed by abstract obscurity, multimodal amalgamation, contextual dependency, and cross-modal (dis-)association. Several insightful use-cases pertaining to fine-grained analysis of harmful memes that have recently shown promise are detection of (i) harmful memes and associated target-types, (ii) harmfully targeted entities, (iii) their role-labels, and (iv) exploring the contextualization of memes. The findings from such investigations will strive to contribute with assistive technologies that can help moderate and monitor multimodal social media traffic and help keep detrimental sections of the digital discourse at bay.
Detecting harmful memes and their targets

Comparing the model’s interpretability for MOMENTA [4] and ViLBERT [5] w.r.t multimodal inputs (right).
Detecting harmful memes is challenging as they typically employ irony, sarcasm, puns, and similes, along with an intelligent blend of impactful visuals. Moreover, while previous work has focused on specific aspects of memes, such as hate speech and propaganda, there needs to be more work on harm in general. The study presented in [4] investigates memes on Covid-19 and US Politics. It aims to bridge this gap by focusing on two tasks: (i) detecting harmful memes, and (ii) identifying the types of social entities they target. Authors also propose MOMENTA (MultimOdal framework for detecting harmful MemEs aNd Their tArgets), a novel multimodal deep neural network that models global and localized multimodal cues (image ROIs and web entities, as shown in Fig. 2, left) to detect harmful memes. Besides establishing interpretability and generalizability, their experiments show that MOMENTA outperforms several competing methodologies. MOMENTA’s contextualized visual modeling affinity is demonstrated via the LIME visualizations depicted in the Fig. 2, right. Despite the better performance, MOMENTA, similar to other comparative approaches like ViLBERT [5], VisualBERT [6], etc., is observed to make errors for cases it has developed biases for.
Characterizing the social entities referred in memes
In addition to detecting harmful, hateful, and offensive memes in general, identifying whom these memes attack (i.e., the “victims”) offers an insightful exploration. Similarly, there could be various narrative frames, like depicting an entity as a hero, a villain, or a victim in memes, the detection of which could enhance the social profiling of harmful multimodal content.
Sharma et al. [7] attempt to address this problem by creating a dataset of memes and their victim(s) in the form of targeted person(s), organization(s), and community(ies), etc. They also propose a multimodal neural framework (DISARM – Detecting vIctimS targeted by hARmful Memes) to detect whether an entity referred to in a given meme is harmfully targeted. An interesting takeaway from this study is the efficacy of such techniques in different evaluation settings based on the prior visibility of the harmful entities to be examined as a training sample. The evaluation shows that DISARM significantly outperforms ten unimodal and multimodal systems. Despite a significant lead of 12% in terms of the performance over a strong multimodal system, MMBT [8], the fact that most of the established multimodal pre-trained and fine-tuned systems scored 46% on average poses the question of scalable semantic multimodal parsing.
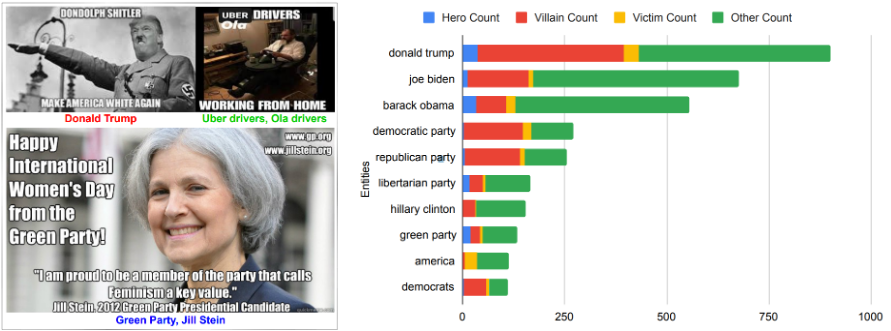
Towards detecting different semantic roles for the entities referred to in memes, Sharma et al. [9] first introduced a shared task, CONSTRAINT@ACL-2022 with an accompanying dataset (HVVMemes) soliciting various solutions for role identification of entities in harmful memes, i.e., detecting who is the “hero,” the “villain,” and the “victim” in the meme, if any. The submissions primarily leveraged large state-of-the-art language models, utilizing meta characteristics like web entities, visual descriptions, etc., and the ensembling of various strategies leading to the highest score of 0.57 macro F1. This reflected the need for better efficacy in the current techniques for performing the semantic reasoning of pragmatics and contextualization required in this task. Sharma et al. [10], however, utilized HVVMemes to propose VECTOR (Visual-semantic role dEteCToR), a robust multi-modal framework for the task, which integrates entity-based contextual information in the multi-modal representation, which led to an enhancement of 1% in the performance, still leaving significant scope of further refinement.
Contextualizing memes via natural language explanations

Since memes often use abstraction while conveying complex ideas, they pose imminent obscurity towards understanding their meaning and implication. This makes their moderation challenging. Sharma et al. [11] introduce a novel task – EXCLAIM, that requires generating explanations for visual semantic role labeling in memes, which were investigated earlier in [9] and [10]. To this end, the authors curate a novel dataset (ExHVV) constituting natural language explanations for the glorification, vilification, and victimization of various entities in memes. Besides benchmarking this new task with several strong unimodal and multimodal baselines, authors propose LUMEN, a novel multimodal, multi-task learning framework that addresses EXCLAIM optimally by jointly learning to predict the correct semantic roles and generating suitable natural language explanations. The striking aspect of LUMEN is that it leverages the enhanced generative capacity of a T5 model while also learning to detect the role labels cooperatively. The authors showcase the remarkable quality of the generated explanations while discussing the limitations caused due to integrating visual descriptions in the textual format and other textual markers in a text-only, generalized generative model like T5, which leads to unfiltered visual and linguistic grounding. This also suggests adequate multimodal attention’s plausible utility while directly leveraging visual and linguistic cues.
In summary, we have presented noteworthy insights from a few of the recent advances in harmful meme analysis, amongst numerous active investigative studies. The increasing commodification of memes in the form of Non-fungible tokens (NFTs), resonated by their nuanced toxicities, and multimodal contextualization, offer immense research opportunities to be explored, towards characterizing and even regulating their dynamic adoption, engagement and virality over social media platforms.
References
[1] Kiela et al., 2020. The hateful memes challenge: detecting hate speech in multimodal memes. In Proceedings of the 34th International Conference on Neural Information Processing Systems (NIPS’20). Curran Associates Inc., Red Hook, NY, USA, Article 220, 2611–2624. [2] Sharma et al., 2020. SemEval-2020 Task 8: Memotion Analysis- the Visuo-Lingual Metaphor!. In Proceedings of the Fourteenth Workshop on Semantic Evaluation, pages 759–773, Barcelona (online). International Committee for Computational Linguistics. [3] Sharma et al., Detecting and Understanding Harmful Memes: A Survey, Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, Survey Track. Pages 5597-5606. [4] Pramanick et al., 2021. MOMENTA: A Multimodal Framework for Detecting Harmful Memes and Their Targets. In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 4439–4455, Punta Cana, Dominican Republic. Association for Computational Linguistics. [5] Lu et al., 2019. ViLBERT: pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. Proceedings of the 33rd International Conference on Neural Information Processing Systems. Curran Associates Inc., Red Hook, NY, USA, Article 2, 13–23. [6] Li at al., 2019. Visualbert: A simple and performant baseline for vision and language. arXiv preprint arXiv:1908.03557. [7] Sharma et al., 2022. DISARM: Detecting the Victims Targeted by Harmful Memes. In Findings of the Association for Computational Linguistics: NAACL 2022, pages 1572–1588, Seattle, United States. Association for Computational Linguistics. [8] Kiela et al., 2019. Supervised Multimodal Bitransformers for Classifying Images and Text. ArXiv, abs/1909.02950. [9] Sharma et al., 2022. Findings of the CONSTRAINT 2022 Shared Task on Detecting the Hero, the Villain, and the Victim in Memes. In Proceedings of the Workshop on Combating Online Hostile Posts in Regional Languages during Emergency Situations, pages 1–11, Dublin, Ireland. Association for Computational Linguistics. [10] Sharma et al., 2023. Characterizing the Entities in Harmful Memes: Who is the Hero, the Villain, the Victim?, EACL’23, ArXiv, abs/2301.11219. [11] Sharma et al., 2023. Sharma, Shivam & Agarwal, Siddhant & Suresh, Tharun & Nakov, Preslav & Akhtar, Md & Charkraborty, Tanmoy. (2022). What do you MEME? Generating Explanations for Visual Semantic Role Labelling in Memes. AAAI’23, ArXiv, abs/2212.00715. [12] Pramanick et al., 2021. Detecting Harmful Memes and Their Targets. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 2783–2796, Online. Association for Computational Linguistics.