



基于弱监督数据学习领域语义表示的科学数据集检索方法研究
基于弱监督数据学习领域语义表示的科学数据集检索方法研究
王继民1 罗鹏程1,2
(1. 北京大学信息管理系 2. 北京大学图书馆)
现有科学数据集的检索方法主要基于查询词与元数据的字面匹配获取数据集,数据集搜索系统如何才能检索并返回给用户语义相关的数据集呢?诸如向量空间模型、BM25概率模型等传统信息检索方法主要基于查询词和待检索文本之间的字面匹配计算相关性得分,然而自然语言中普遍存在同义词、近义词、相关词等语言现象,这使得传统信息检索模型在语义检索上存在一定的困难。近些年,BERT等基于Transformer的预训练语言模型在自然语言处理中展现出强大的特征抽取能力,能够从文本中抽取出深层的语义特征。利用预训练语言模型将用户查询和待检索文本表示为语义向量,并基于向量之间的相似度可实现信息的检索(这类方法被称为稠密检索模型)。在国家社会科学基金重点项目“开放科学数据集统一发现的关键问题与平台构建研究”的支持下,论文《Learning Domain-specific Semantic Representation from Weakly Supervised Data to Improve Research Dataset Retrieval》利用稠密检索模型实现数据集的语义检索。
—现有科学数据集的检索方法主要基于查询词与元数据的字面匹配获取数据集,数据集搜索系统如何才能检索并返回给用户语义相关的数据集呢?—
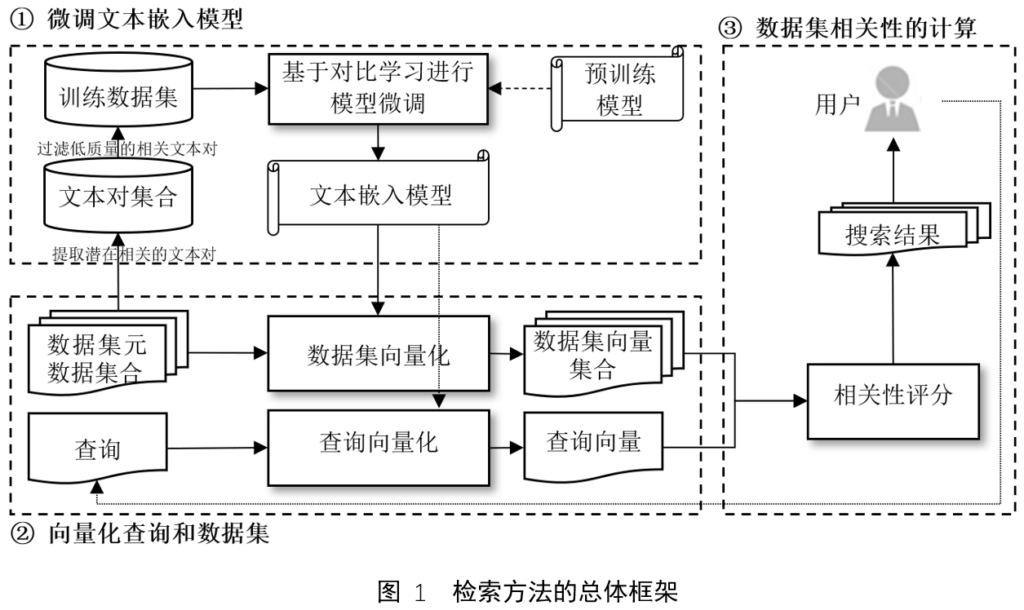
稠密检索模型需要在领域特定的训练数据上进行模型的调优,然而针对特定领域的数据集检索常常缺乏训练数据,如何才能训练优质的稠密检索模型实现数据集的语义检索呢?考虑到同一个数据集的标题、关键词和描述字段的文本内容之间具有一定语义相关性,因此将标题或关键词看作用户查询,将描述文本看作相关文本,则可以构造出领域相关的弱监督训练数据。图1给出了本研究基于弱监督数据学习领域语义表示的科学数据集检索方法的整体框架。该方法主要包括三个部分:微调文本嵌入模型、向量化查询和数据集、数据集相关性计算。在微调文本嵌入模型中,基于构造的弱监督训练数据集并利用对比学习方法,获取适合特定领域数据集检索的文本嵌入模型。在向量化查询和数据集中,利用文本嵌入模型将用户查询和数据集的元数据表示为向量。在数据集相关性计算中,利用查询向量和数据集向量之间的相似度,可获取语义相关的数据集检索结果。
前述数据集检索方法在逻辑上具有一定的合理性,但其真实的检索效果如何呢?为了验证检索方法的效果,本研究构造了一个测评数据集。该数据集包含了约10万人文社科数据集的元数据,15个用户查询和约3000个标注的检索结果。将传统信息检索模型、基于通用领域文本嵌入的稠密检索模型、以及本研究领域特定的稠密检索模型进行实验测评。结果显示:与BM25模型相比,本研究方法在NDCG@10上能够提高5.84个百分点;与基于通用领域文本嵌入的稠密检索模型相比,本研究方法在NDCG@10上能够提高4.75个百分点。由此可见,本研究的检索模型能够学习到领域特定的语义知识,从而实现更好的数据集检索效果。
参考文献
Luo, P., Hong, L., Wang, J., Wang, S., Guo, X., Gao, Z., & Cho, S. W. (2022). Learning Domain-specific Semantic Representation from Weakly Supervised Data to Improve Research Dataset Retrieval. Proceedings of the Association for Information Science and Technology, 59(1), 205-214.
APA引用格式: Luo, P & Wang, J. (2022, November 18).基于弱监督数据学习领域语义表示的科学数据集检索方法研究. Information Matters, Vol. 2, Issue 11. https://informationmatters.org/2022/11/基于弱监督数据学习领域语义表示的科学数据集检索方法研究/
